
I Built A Dashboard Because AI Limits Changed How I Work
I pay for the highest consumer-tier AI coding subscriptions I can justify.
I still hit limits.
That sounds like a tooling complaint, but I do not think it is. I think it is a signal about how engineering work is changing.
When AI becomes part of your daily operating model, token usage stops being an abstract platform detail. It becomes workflow telemetry. It tells you when you are carrying too much context, when one thread has become a junk drawer, when you are asking the wrong tool to do the wrong job, and when your personal productivity system is starting to leak.
That is why I built AI Spend Live.
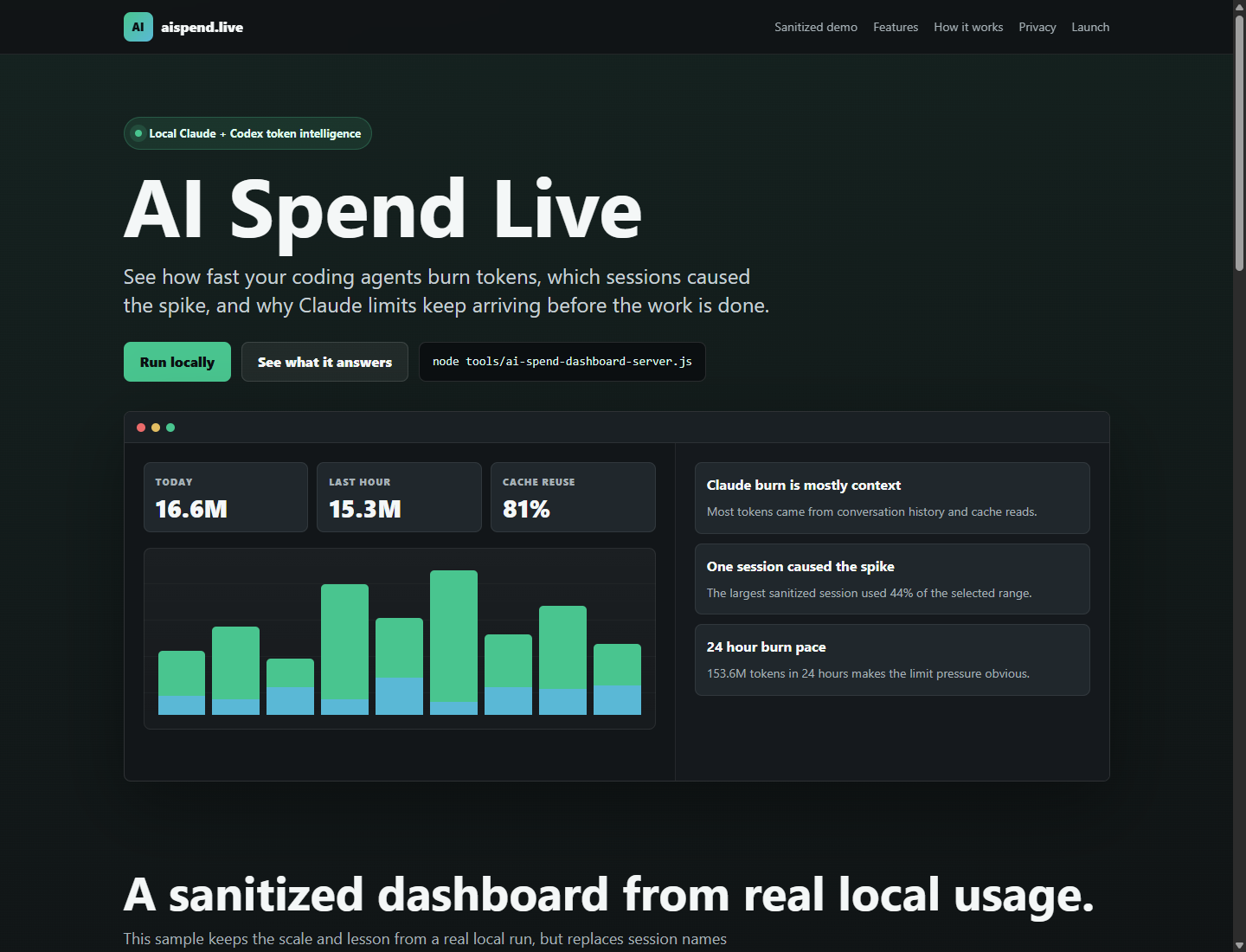
The tool reads local Claude and Codex usage logs and turns them into a local dashboard. I do not need prompt text to learn what matters. I need burn rate, session concentration, biggest turns, provider split, model split, and whether the context window is being used like a tool or like a landfill.
The important part is not the dashboard.
The important part is the behavior it changes.
The Limit Is Not Always The Problem
I am using paid Claude and Codex subscriptions, and I still run into limits. My first instinct used to be simple: I must be doing a lot of work.
That was true, but incomplete.
When I looked at a recent seven-day window, the usage pattern was much more interesting:
- 7.4 billion tokens
- 23,800 turns
- 34 sessions
- about $12,600 in API-equivalent usage
- Claude: about 5.8 billion tokens
- Codex: about 1.7 billion tokens
Those dollar numbers are not my subscription bill. They are API-equivalent estimates. I use them as a scale signal, not as an accounting statement.
Still, the scale matters.
If a single week of local AI-assisted engineering activity can represent that much equivalent usage, then the bottleneck is not access to AI. The bottleneck is operating discipline.
One Session Can Become The Whole Problem
The number that changed my behavior was not the total.
It was concentration.
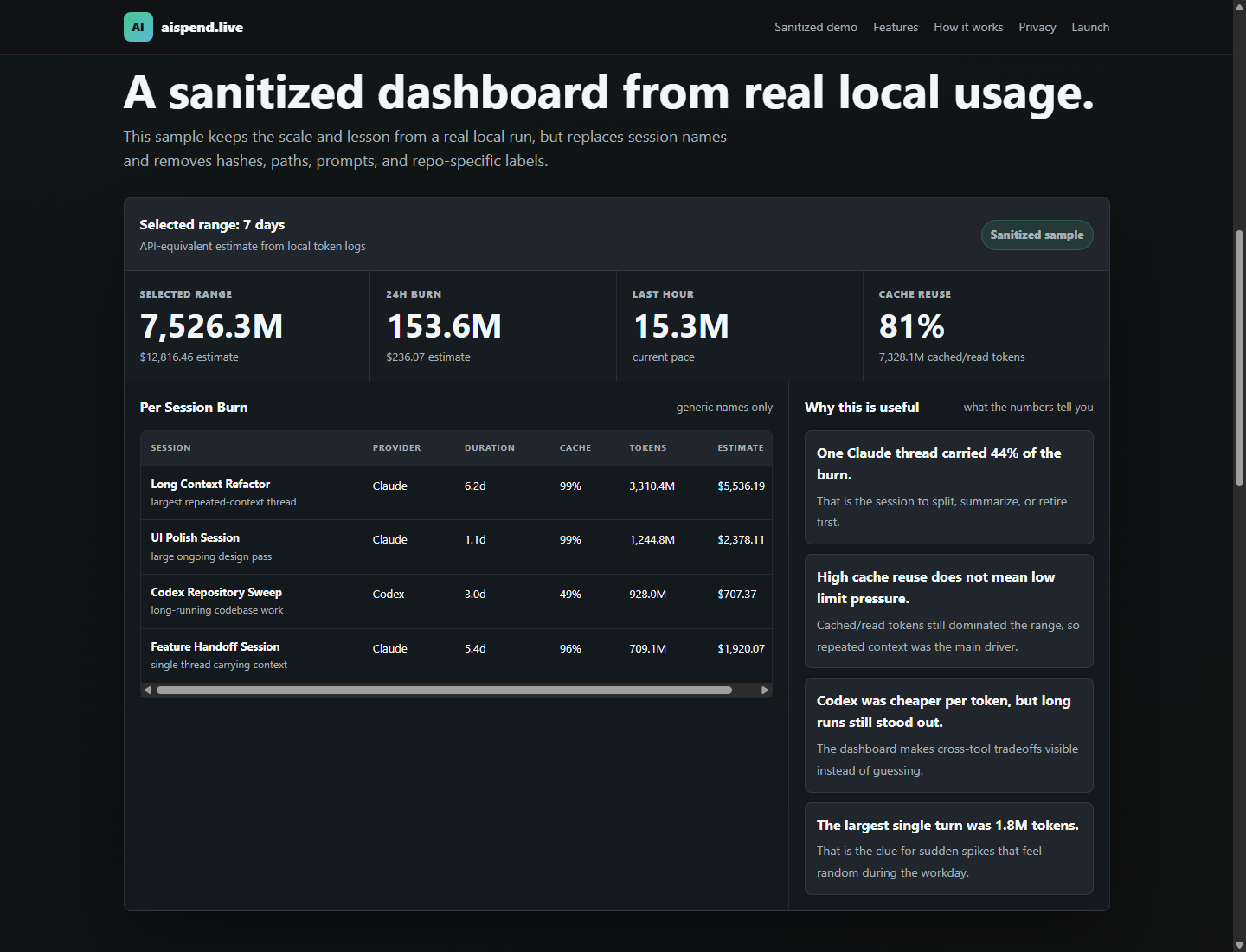
One long-running Claude session accounted for roughly 44% of the selected token usage. That one session represented about 3.3 billion tokens and roughly $5,456 of API-equivalent cost.
I am deliberately not naming what that session was. The title is not the lesson. The pattern is.
It was a session that stayed open too long. It accumulated different prompts, different decisions, different bits of context, and different follow-up asks. Each new prompt felt cheap in the moment because the thread was already there.
But a long context has gravity.
The more history it carries, the more every future request pays for that history. Cached tokens may be cheaper than fresh tokens, and they may make the system faster, but they are not free in the only sense that matters when you are hitting limits: they still consume scarce capacity.
That changed my rule of thumb.
If a session changes purpose, I restart it. If the thread is mostly useful as history, I summarize it and restart. If I am keeping it open because I am afraid to lose context, that context probably belongs in a document, test, issue, or plan instead of a chat transcript.
The Biggest Turn Is A Leadership Smell
The largest single turn in that same window was about 1.8 million tokens and about $44 API-equivalent.
Again, the specific work does not matter.
The smell matters.
A huge turn usually means one of a few things:
- the prompt pulled in too much repo context
- the session history was doing too much work
- the ask was too broad
- the handoff artifacts were not good enough
- the wrong tool was being used for the shape of the task
That is a leadership problem before it is a tooling problem.
At a team level, the same pattern shows up as meetings with too many people, projects with unclear ownership, or status reports that carry the whole history of the organization every time someone asks a question.
AI did not create that problem. It made it measurable.
I Now Route Work Differently
The practical change is that I treat Claude and Codex less like interchangeable chat boxes and more like different work surfaces.
I use Codex heavily when the job is bounded, repo-shaped, and execution-oriented: inspect the code, make a scoped change, run the checks, report the diff. It is strongest when I can define the write surface and validation path clearly.
I use Claude more when the job is judgment-heavy: architecture tradeoffs, critique, synthesis, product framing, planning, or when I want a second strong point of view before I move.
That split is not about which model is “better.” It is about preserving scarce attention and scarce context.
If I ask a judgment tool to churn through endless mechanical work, I burn the thing it is good at. If I ask an execution tool to infer a vague strategy, I create rework. The leverage comes from matching the work to the tool and keeping the session shape clean.
The New Personal Operating Model
Here are the habits I am moving toward:
- Start with a bounded ask, not a sprawling ambition.
- Use one session per work surface.
- Summarize and restart before the context becomes expensive sludge.
- Move durable context into files, plans, tests, and docs.
- Watch the largest turns, not just the total usage.
- Treat cached context as capacity, not magic.
- Use multiple sessions when the work can be split cleanly.
- Close sessions when their job is done.
- Ask whether the next prompt needs history or just a crisp handoff.
This is the AI version of engineering hygiene.
The same way high-performing teams learned to care about build times, flaky tests, cycle time, incident review, and code ownership, AI-native teams will need to care about context flow.
Not because tokens are precious in themselves.
Because wasted context is usually wasted clarity.
What This Means For Engineering Leaders
I do not think the future engineering leader wins by casually saying, “Everyone should use AI more.”
That is too shallow.
The better question is: what operating model makes AI usage compound instead of sprawl?
Can your team turn good prompts into reusable workflows? Can it turn repeated context into durable documentation? Can it split work across agents without creating integration chaos? Can it validate faster than it generates? Can it see when a tool is producing motion instead of progress?
Those are leadership questions.
The interesting frontier is not one person producing more code. It is an organization learning how to scale output without scaling confusion at the same rate.
For me, AI Spend Live is a small tool pointed at that bigger problem.
It helps me see when I am being effective, when I am being lazy with context, and when the AI session has become a substitute for a better system.
The goal is not to spend fewer tokens at all costs.
The goal is to spend them on the work that actually deserves them.